 While browsing Metalink you may find yourself surprised with such a Language selector. Wow i thought, maybe this is the next best thing. Soon we will be typing translate.google.com/ibmpower_to_linux64.
While browsing Metalink you may find yourself surprised with such a Language selector. Wow i thought, maybe this is the next best thing. Soon we will be typing translate.google.com/ibmpower_to_linux64.
Friday, December 19, 2008
Babel: a set of languages
While browsing Metalink you may find yourself surprised with such a Language selector. Wow i thought, maybe this is the next best thing. Soon we will be typing translate.google.com/ibmpower_to_linux64.
Thursday, December 18, 2008
We are sorry. Till the death (yours We mean). Sorry
Atsiprašome vartotojų, gavusių klaidingą sąskaitą
Šią savaitę dėl techninių nesklandumų dalis vartotojų gavo sąskaitą su eilute „Skola iki mirties". Eilutė atsirado dėl programinės klaidos sąskaitų formavimo metu.
Labai atsiprašome vartotojų, gavusių tokią sąskaitą.
VĮ „Visagino energija" administracija
Atsiprašome vartotojų, gavusių klaidingą sąskaitą
Šią savaitę dėl techninių nesklandumų dalis vartotojų gavo sąskaitą su eilute „Skola iki mirties". Eilutė atsirado dėl programinės klaidos sąskaitų formavimo metu.
Labai atsiprašome vartotojų, gavusių tokią sąskaitą.
VĮ „Visagino energija" administracija
Wednesday, December 17, 2008
Cool name

#2. Hangman Utility – The Hang Manager (hangman) utility is a new 11g tool to detect database bottlenecks.
Friday, December 12, 2008
Special characters in shell
 If you seeing some special characters using less, then you are in the right place. Bumped into this problem last evening, when i was trying to parse an utf8 coded html. You may write special characters in shell using (ctrl+v) (ctrl+x), where x is your desired character.
If you seeing some special characters using less, then you are in the right place. Bumped into this problem last evening, when i was trying to parse an utf8 coded html. You may write special characters in shell using (ctrl+v) (ctrl+x), where x is your desired character.When you use for example ^M in bash script - its not recognized, even if you edit it vith vi. I found the solution in perl forum.
grep ^D
(type ctrl-V ctrl-D)
perl -ne 'print if /\cD/'
Use \cx notation in shell scripting, where x is your desired character. Example:
less ubs.html | tr ',' '.' | sed 's/\cM/č/g' > ubs_normal.html
Thursday, December 11, 2008
Crawling AJAX in practice. Part 1
Some theory
Traditionally, a web spider system is tasked with connecting to a server, pulling down the HTML document, scanning the document for anchor links to other HTTP URLs and repeating the same process on all of the discovered URLs. Each URL represents a different state of the traditional web site. In an AJAX application, much of the page content isn't contained in the HTML document, but is dynamically inserted by Javascript during page load. Furthermore, anchor links can trigger Javascript events instead of pointing to other documents. The state of the application is defined by the series of Javascript events that were triggered after page load. The result is that the traditional spider is only able to see a small fraction of the site's content and is unable to index any of the application's state information.
Some findings
I've googled around for a few days and have found various information about crawling tools. There are more, but some are forgotten to mention or haven't been tried. Here is a quick summary of tools for getting page source.
1) Right click, View page source. Well, a simple way to get page source, but you fall laughing when you see the dynamic page source. I was playing around with ubs.com -> quotes -> instruments.
2) Perl::Mechanize. It's a useful tool, i was happy using it, but the result is sadly though - static. It fills forms and follows links, but the final page source is static. It digs text, digs .css underneath, but avoids JavaScript. You can get a page source browsing only static version of webpage (which ubs.com has). This tools is useful for sabotage, for example you create disposable email accounts, vote online for a car of the year, read the passkey from you temp email, vote and repeat the loop again. No user interface needed, while testing use browser and
compare it to Mechanize agent->content.
3) Various Firefox extensions. Crap, the target was to build a GUI-less mechanism, these implementations though require user interaction. Extensions are based on tracking AJAX requests, recording user actions (like macros in Office). iMacros, ChickenFoot, Selenium. Here are the names. iMacros are error sensitive, for example first visit and getting a cookie differs from the subsequent visits. Mechanize for example is error proof for such actions. I haven't found use of other extensions, because most of them doesn't work on Minefield, nor RedHat's Firefox one point zero something.
4) Ruby + Watir. AJAX crawling after all! But there is a huge "but" - presenting IE. There are also Watir implementations on FF and Safari, haven't tested them. Ruby is also error proof, and i have achieved some progress, but the result is STATIC. Spent half a day looking for a way to save page content to file, spent one day more for looking how to get a full page source, but didn't manage that. Please inform me if i'm wrong, but anyways - skype has an emotion for coding on windows: (puke).
5) Yes you are right, saved the best for dessert. XULRunner + Crowbar. This stuff works and rocks and has an implementation, more about it in Part 2. Here is a quote: "...a server-side headless mozilla-based browser". It even sounds promising. It runs as a daemon, you can ask it, push it, get contents, and get AJAXed source. Its a browser based execution environment with a scraping tool on it. After you get your desired page source, its kinda trash: no newlines, bunch of HTML tags. Then there are few solutions - pass it to Lynx or process manually with a custom C code parser. At last we have the numbers, not a JavaScript function names.
Clarification
The purpose of this task is not to exactly crawl from one page to other, its only numbers that are pushed (AJAX'ed) via JavaScript that matters.
Part 2
Traditionally, a web spider system is tasked with connecting to a server, pulling down the HTML document, scanning the document for anchor links to other HTTP URLs and repeating the same process on all of the discovered URLs. Each URL represents a different state of the traditional web site. In an AJAX application, much of the page content isn't contained in the HTML document, but is dynamically inserted by Javascript during page load. Furthermore, anchor links can trigger Javascript events instead of pointing to other documents. The state of the application is defined by the series of Javascript events that were triggered after page load. The result is that the traditional spider is only able to see a small fraction of the site's content and is unable to index any of the application's state information.
Some findings
I've googled around for a few days and have found various information about crawling tools. There are more, but some are forgotten to mention or haven't been tried. Here is a quick summary of tools for getting page source.
1) Right click, View page source. Well, a simple way to get page source, but you fall laughing when you see the dynamic page source. I was playing around with ubs.com -> quotes -> instruments.
2) Perl::Mechanize. It's a useful tool, i was happy using it, but the result is sadly though - static. It fills forms and follows links, but the final page source is static. It digs text, digs .css underneath, but avoids JavaScript. You can get a page source browsing only static version of webpage (which ubs.com has). This tools is useful for sabotage, for example you create disposable email accounts, vote online for a car of the year, read the passkey from you temp email, vote and repeat the loop again. No user interface needed, while testing use browser and
compare it to Mechanize agent->content.
3) Various Firefox extensions. Crap, the target was to build a GUI-less mechanism, these implementations though require user interaction. Extensions are based on tracking AJAX requests, recording user actions (like macros in Office). iMacros, ChickenFoot, Selenium. Here are the names. iMacros are error sensitive, for example first visit and getting a cookie differs from the subsequent visits. Mechanize for example is error proof for such actions. I haven't found use of other extensions, because most of them doesn't work on Minefield, nor RedHat's Firefox one point zero something.
4) Ruby + Watir. AJAX crawling after all! But there is a huge "but" - presenting IE. There are also Watir implementations on FF and Safari, haven't tested them. Ruby is also error proof, and i have achieved some progress, but the result is STATIC. Spent half a day looking for a way to save page content to file, spent one day more for looking how to get a full page source, but didn't manage that. Please inform me if i'm wrong, but anyways - skype has an emotion for coding on windows: (puke).
5) Yes you are right, saved the best for dessert. XULRunner + Crowbar. This stuff works and rocks and has an implementation, more about it in Part 2. Here is a quote: "...a server-side headless mozilla-based browser". It even sounds promising. It runs as a daemon, you can ask it, push it, get contents, and get AJAXed source. Its a browser based execution environment with a scraping tool on it. After you get your desired page source, its kinda trash: no newlines, bunch of HTML tags. Then there are few solutions - pass it to Lynx or process manually with a custom C code parser. At last we have the numbers, not a JavaScript function names.
Clarification
The purpose of this task is not to exactly crawl from one page to other, its only numbers that are pushed (AJAX'ed) via JavaScript that matters.
Part 2
Friday, December 5, 2008
MD create, overwrite question
We had an argue today with my friend DeepM, 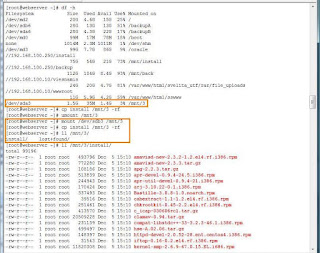
does making software raid1 with mdadm overwrites the partition or at least garbages its superblock / partition table / file system, if someone bumps to this question one day in ones life, here is the answer: NO, it does not.
I took two sata partitions sda3 and sdb3, mkfs.ext3, copy some stuff to both of them.
In picture 1, you can see the contents.
Next i create md device using both partitions with command:
mdadm -Cv /dev/md1 -l1 -n2 /dev/sda3 /dev/sdb3
Mdadm kindly warns me, that partition, contains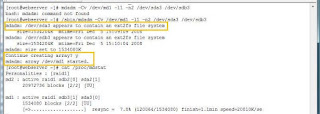
file system with (probably) files in it. Thank you, i know what i'm doing. Just press "y".
Resync process starts, 1.5G takes a few seconds to resync.
Picture 3 below: resync in progress.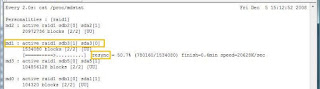
After process is done, i remount newly created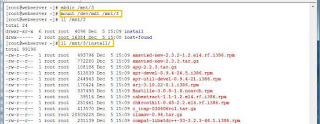 md1 device, check its contents and VOILA - everything is in place.
md1 device, check its contents and VOILA - everything is in place.

does making software raid1 with mdadm overwrites the partition or at least garbages its superblock / partition table / file system, if someone bumps to this question one day in ones life, here is the answer: NO, it does not.
I took two sata partitions sda3 and sdb3, mkfs.ext3, copy some stuff to both of them.
In picture 1, you can see the contents.
Next i create md device using both partitions with command:
mdadm -Cv /dev/md1 -l1 -n2 /dev/sda3 /dev/sdb3
Mdadm kindly warns me, that partition, contains

file system with (probably) files in it. Thank you, i know what i'm doing. Just press "y".
Resync process starts, 1.5G takes a few seconds to resync.
Picture 3 below: resync in progress.

After process is done, i remount newly created
 md1 device, check its contents and VOILA - everything is in place.
md1 device, check its contents and VOILA - everything is in place.
New corner on the blog
Quote from an unspecified source:
#1. Authorized users should obtain the OSX files from Apple. It is illegal to obtain them from torrent sites by searching under the following keywords: “VMWare files for patched Mac OS X Tiger Intel”.
#1. Authorized users should obtain the OSX files from Apple. It is illegal to obtain them from torrent sites by searching under the following keywords: “VMWare files for patched Mac OS X Tiger Intel”.
Subscribe to:
Posts (Atom)